大端序/小端序
字节序即字节的存储顺序,如果数据都是单字节的,那怎么存储无所谓了,但是对于多字节数据,比如int,double等,就要考虑存储的顺序了。字节序是硬件层面的东西,通常只和你使用的处理器架构有关,而和编程语言无关。字节序分为大端序和小端序。
-
大端序:将高序字节存储在起始地址,一个占有4个字节类型的数据0x00112233在内存中如下分布:

-
小端序:将低序字节存储在起始地址,数据0x00112233在内存中如下分布:
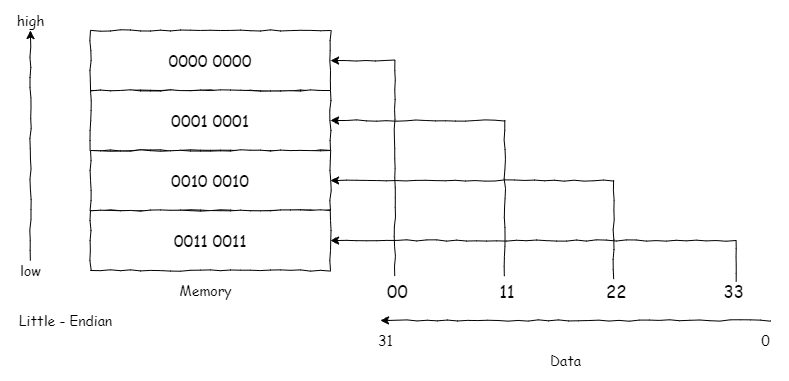
比特序/位域
位域的写入顺序和当前系统字节序有关:先定义的位域在大端环境从最高bit位(
MSB)开始分配。如果为小端环境则先定义的位域从最低bit位(LSB)开始分配。(CPU操作内存还是以字节为单位的)struct bitfield { uint8_t a:1; uint8_t b:2; uint8_t c:3; uint8_t d:2; }bf; bf.a = 1; bf.b = 2; bf.c = 3; bf.d = 3; -
大端系统:
struct bitfield bf在内存中如下分布: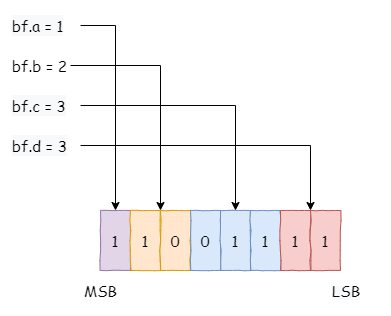
-
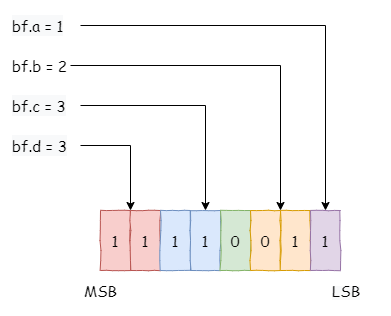
小端系统:
struct bitfield bf在内存中如下分布:
比特的发送、接收顺序对CPU、软件都是不可见的,(对诸如PHY的serdes(串行器和解串器)以及网卡写总线的硬件设计是非常重要的)因为我们的网卡会给我们处理这种转换,在发送的时候按照小端序发送比特位,在接收的时候网卡会把接收到的比特序转换成主机的比特序,下面是一个小端机器发送一个int整型给一个大端机器的示意图:
因为不同的平台的比特序是不同的,但是我们定义的位域需要根据平台的大小端进行转换,以iphdr为例:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__u16 tot_len;
__u16 id;
__u16 frag_off;
__u8 ttl;
__u8 protocol;
__u16 check;
__u32 saddr;
__u32 daddr;
/*The options start here. */
};
网络序/主机序
- 网络序:采用大端的排序方式
- 主机序:不同的CPU有不同的字节序类型这些字节序是指整数在内存中保存的顺序,CPU上运行不同的操作系统,字节序也是不同的
| 处理器 | 操作系统 | 字节排序 |
|---|---|---|
| Alpha | 全部 | Little endian |
| HP-PA | NT | Little endian |
| HP-PA | UNIX | Big endian |
| Intelx86 | 全部 | Little endian |
| Motorola680x | 全部 | Big endian |
| MIPS | NT | Little endian |
| MIPS | UNIX | Big endian |
| PowerPC | NT | Little endian |
| PowerPC | 非NT | Big endian |
| RS/6000 | UNIX | Big endian |
| SPARC | UNIX | Big endian |
| IXP1200 ARM核心 | 全部 | Little endian |