内核中自旋锁、信号量/mutex、读写锁/顺序锁、RCU介绍。
自旋锁
为什么需要自旋锁
很多时候我们并不能采用其他的锁,比如读写锁、互斥锁、信号量等。一方面这些锁会发生上下文切换,他的时间是不可预期的,对于一些简单的、极短的临界区完全是一种性能损耗;另一方面在中断上下文是不允许睡眠的,除了自旋锁以外的其他任何形式的锁都有可能导致睡眠或者进程切换,这是违背了中断的设计初衷,会发生不可预知的错误。基于两点,我们需要自旋锁,他是不可替代的。
为什么自旋锁会禁止抢占
这一点其实很好理解,当一个 CPU 获取到一把自旋锁之后,开始执行临界区代码,此时假设他的时间片运转完毕,进程调度会主动触发调度将其调走,执行另一个线程/进程,结果恰巧了这个线程/进程也需要用到该自旋锁,而上一个线程/进程还在停留在临界区内未释放锁,导致本进程无法获取到锁而形成死锁,所以自旋锁为了规避此类情形的出现从而直接禁止对已经开始运行的临界区设置禁止抢占标志。
为什么临界区禁止睡眠
如果自旋锁锁住以后进入睡眠,而此时又不能进行处理器抢占,内核的调取器无法调取其他进程获得该 CPU,从而导致该 CPU 被挂起;同时该进程也无法自唤醒且一直持有该自旋锁,进一步会导致其他使用该自旋锁的位置出现死锁。
spin_lock 系列的分别
每一种锁出现都有自己的原因,spin_lock 系列的锁就是为了解决这一个又一个的问题才会新增的各种自旋锁变种,这也符合现代计算机代码设计逻辑,首先是解决有无问题之后再解决崩溃问题,最后才是性能问题,没有什么设计能够逃得出这样一个框架。
spin_lock 出现的原因上文已经介绍过了,目标就是为了解决当前内核中,某些场景下快速访问临界区的问题而存在的,所以他禁止了调度器抢占,所以不存在任何其他的进程会抢占该 CPU 的情况。但是,现代计算机为了能够更快的响应各种外部消息,所以存在各种类型的中断,比如网卡中断的到来,就一定会打断正在执行的 CPU 的进程,哪怕是当前的程序被 spin_lock 给锁住了,假设当前的中断也需要访问该 spin_lock 锁,那么就会导致死锁发生,如图:
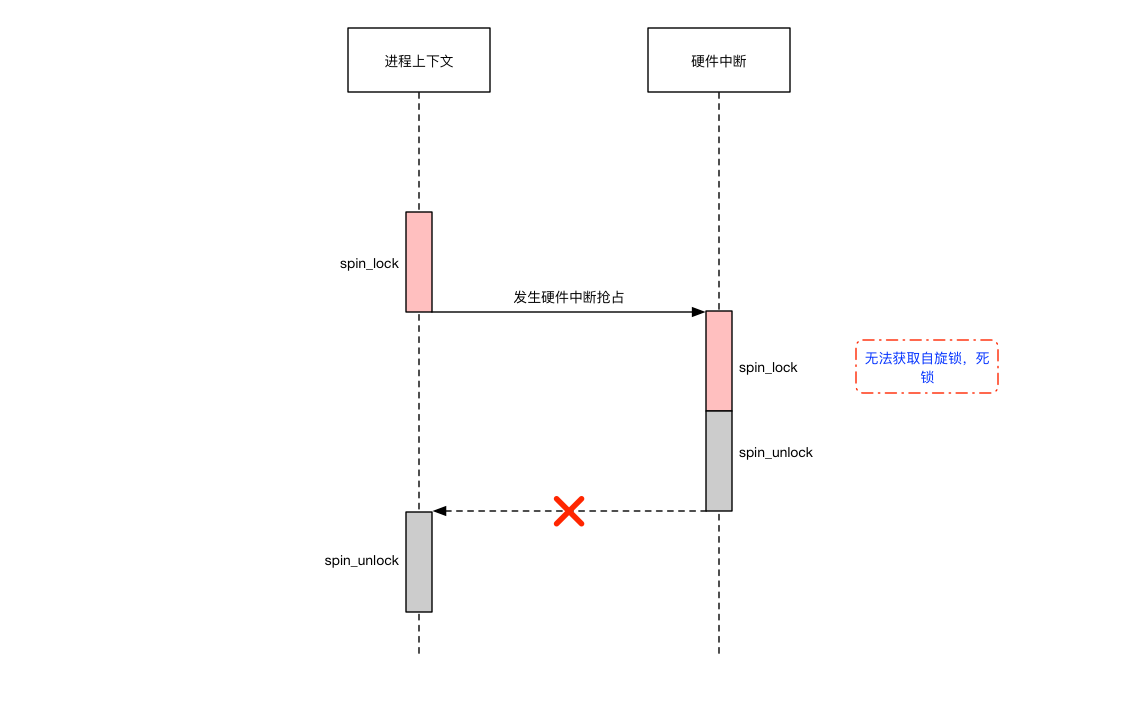
所以为了应对自旋锁同时出现在硬件中断和进程上下文的情况,所以应该在进程执行临界区代码段的自旋锁上锁之前,首先就应该关闭当前 CPU 的中断,这样无论你发生什么情况,一旦被锁上就不再会被任何的情况抢走 CPU,这就是 spin_lock_irq 出现的原因,当然,由于需要关闭中断,会导致系统的响应降低,而且还会执行更多的代码,可能会导致性能下降。
那么 spin_lock_irqsave 又为何需要存在,之前说过每一种类型变种的出现都是为了解决实际问题,那么这个类型锁的出现也是为了解决一些实际问题。如图所示:

从图中可以看出,当进程在执行第一个 spin_lock_irq(&lock1) 时已经关闭了中断,然后继续获取第二个自旋锁spin_lock_irq(&lock2),当 lock2 解锁后且 lock1 未解锁前这一段区域处于一种硬件中断开启的状态,这段代码仍然处于 lock1 的临界区,如果此时硬件中断也需要申请 lock1 锁会导致死锁,这是因为 spin_unlock_irq 在解锁时一定会将本地 CPU 的中断打开,从而导致硬件中断可以重新强制抢占 CPU,所以最好的方式就是 lock2 在锁之前保存当前的中断状态,在解锁时恢复当前的中断状态,这也就是 spin_lock_irqsave 需要存在的原因。自然地,这是一种更为线程安全的方案,但是他会带来比前面几种更加多的性能损耗。
什么场合使用什么类型的自旋锁
既然都已经了解了三种自旋锁的变种,那么什么情况下适合什么样的锁呢?
spin_lock 使用场景
首先如果整个临界区都只位于进程上下文或者工作队列中,那么只需要采用最为方便的 spin_lock 即可,因为他不会发生中断抢占锁的情况,哪怕中断抢占进程上下文也不会导致中断由于申请自旋锁而导致死锁。
还有一种情况就是在硬件中断中可以考虑使用 spin_lock 即可,因为硬件中断不存在嵌套(未必一定是这样,与平台有关),所以只需要简单的上锁即可, 可以不需要关闭中断,保存堆栈等。
spin_lock_irq 使用场景
这个锁的变种适合在进程上下文/软中断 + 硬件中断这样的组合中使用,taskset 也是属于软中断的一种,所以也归在此类。当然,这种类型的变种同样适合软中断/taskset + 进程上下文的组合,因为关闭了硬件中断,从源头就禁止执行软中断代码,不过,对于这种类型的中断最好的方式是使用 spin_lock_bh 的方式,因为他只锁定软中断代码执行,而不关闭硬件中断,这样性能损耗更小。
spin_lock_irqsave 使用场景
这种类型的使用方式是最为安全以及便捷的,毕竟不需要考虑会不会发生死锁的问题(代码本身引入的死锁不在此类),但是他也是性能损耗最大的代码,能不使用尽量不适用,在高速设备上,自旋锁已然成为了一种降低性能的瓶颈。他最好只出现在在需要尝试 spin_lock 之前无法确定是否已经关闭中断的代码才使用,如果代码能够确定在执行锁之前中断一定是打开的,那么使用 spin_lock_irq 是更佳的选择。
spin_lock_bh 使用场景
这种类型的变种是一种比 spin_lock_irq 更轻量的变种,只关闭中断底半部,其实就是关闭了软中断、Tasklet以及 Timer 等的一个抢占能力,如果开发者确定编写的代码临界区只存在软中断/Tasklet/Timer + 进程上下文这样的组合,则最好考虑使用 spin_lock_bh 这样的锁来禁止软中断进行抢占。还有就是软中断与软中断自我抢占临界区访问时,也需要使用 spin_lock_bh 以上的中断锁,因为有可能软中断在执行的过程中,自己被硬件中断打断,然后又执行到同样的代码,在别的 CPU 执行还好说,毕竟软中断可以在不同的 CPU 上执行同一个中断函数,但是假设不幸运行在同一个 CPU 上,则会导致死锁。Tasklet 由于在运行过程中钟只会运行一个实例,所以不存在死锁问题,Tasklet与 Tasklet 的锁竞争只需要使用 spin_lock 即可。
信号量和mutex
网上有一篇关于信号量和mutex的深入分析的介绍 ,最后作者有一段总结:
具体可以参照:https://blog.csdn.net/weixin_32521765/article/details/116923700
我们看到对mutex的优化其实遵循了代码优化的一般原则,即集中优化整个代码执行中出现的hot-spot(引申到高概率spot)。因为在实际使用当中,大多数情况 下,mutex_lock与mutex_unlock之间的代码都比较简短,使得获得锁的进程可以很快释放锁(因此,从性能优化的角度,这个也可以作为使 用mutex的一条一般原则)。如果系统中大部分拥有互斥锁的进程在mutex_lock与unlock之间执行时间比较长,那么相对于使用 semaphore,我相信使用mutex会使得系统性能降低:因为很大的概率,mutex都经过一段spin(虽然这段时间极短)之后最终还是进入 sleep,而semaphore则直接进入sleep,没有了spin的过程。
读写锁和顺序锁
//定义读写锁
rwlock_t rwlock;
//初始化读写锁
rwlock_init(&rwlock);
//读锁定
read_lock(&rwlock);
//读锁定并关闭中断
read_lock_irq(&rwlock);
//读解锁
read_unlock(&rwlock);
//读解锁并恢复中断
read_unlock_irqrestore(&rwlock);
//写锁定
write_lock(&rwlock);
//写锁定并关闭中断
write_lock_irq(&rwlock);
//写解锁
write_unlock(&rwlock);
//写解锁并恢复中断
write_unlock_irqrestore(&rwlock);
//定义顺序锁
seqlock_t seq_lock;
//初始化顺序锁
seqlock_init(&seq_lock);
//写锁定
write_seqlock(seqlock_t * sl);
write_seqlock_irq(seqlock_t * sl);
//写解锁
write_sequnlock(seqlock_t * sl);
write_sequnlock_irqrestore(seqlock_t * sl);
//读申请
unsigned int read_seqbegin(const seqlock_t * sl);
//读有效判定
int read_seqretry(const seqlock_t * sl, unsigned start);
//demo
do
{
unsigned int seqnum=read_seqbegin(&seqlock);
//读操作 .
}while(read_seqretry(&seqlock,seqnum));
- 读写锁和顺序锁相同点:读操作和读操作不互斥、读写互斥、写写互斥
- 读写锁和顺序锁不同点:读写锁读优先,即写操作会等所有读操作完成,才会进入;顺序锁写优先,demo中的
do while就是读者发现写操作修改数据,尝试再次读取。即如果当前有其他读操作,写操作也会执行。
RCU
RCU在驱动中用的相对比较少,可以参考这篇文章:https://blog.csdn.net/xabc3000/article/details/15335131